
Comment Solana va t-il passer à l’échelle ? Entrevue technique de Cloudbreak
Au travers de nos précédentes parutions traitant des technologies liées à la blockchain Solana, nous avons décortiqué des éléments tels que le POH, Tower BFT, Turbine, Sealevel, Gulf Stream. Dans le papier suivant, nous aborderons les problématiques de mémoire vive et son optimisation.
En effet, le code n’est pas tout. L’architecture des informations mais aussi l’optimisation des matériaux disponibles sont des éléments cruciaux dans la performance des technologies blockchain. Découvrons Cloudbreak, l’un des 7 piliers de Solana qui a été pensé pour améliorer la scalabilité des transactions.
Cet article vous est proposé dans le cadre d’une campagne de communication éducative soutenue par Solana.
Blockchain : la mémoire et ses limites
Il existe plusieurs solutions de mise à l’échelle pour les différentes blockchains et DAG disponibles. Certaines comme Ethereum, utilisent ou prévoient d’utiliser la fragmentation, « sharding » en anglais. Ce n’est pas le cas de la blockchain Solana, qui a été conçue pour s’adapter aux matériaux existants.
L’optimisation des caractéristiques logicielles et de consensus n’est pas suffisante. En effet, l’usage des ressources disponibles doit lui aussi être pris en compte. Souvent, le type de mémoire utilisé pour le suivi des soldes de chaque compte devient rapidement un goulot d’étranglement, autant en termes de taille qu’en termes de vitesse d’accès.
Par exemple, LevelDB, un système de base de données utilisé par beaucoup de cryptomonnaies, ne supporte pas plus de 5,000 transactions par seconde via un même ordinateur. Cette limite est réelle puisque la machine virtuelle n’est pas en mesure de faire bon usage des capacités de lecture/écriture simultanées du matériel.
Pour résoudre cette problématique, une solution basée sur le stockage de ces données dans la mémoire vive pourrait être imaginée. Cependant, les soldes de compte prennent énormément de place. L’ordinateur d’un utilisateur moyen n’a que très rarement la quantité de mémoire requise.
Une autre alternative pourrait se caractériser par l’utilisation de SSD, qui restent à priori raisonnablement rapides, tout en ayant un coût par gigaoctet intéressant : en moyenne 30 fois moins cher que la mémoire vive. Cependant, celles-ci semblent inadaptés.
Prenons l’exemple de l’un des derniers SSD NVMe Samsung, qui, de par sa conception, possède une vitesse de lecture/écriture jusqu’à 10 fois plus rapide que des SSD SATA traditionnels. Voici ses spécifications :

Dans une blockchain, une transaction simple qui vise à dépenser des pièces requiert un certain nombre d’actions pour être concrétisée :
- Deux lectures de soldes de compte,
- Une écriture sur un compte.
Or, les adresses desdits comptes sont des clés publiques cryptographiques, totalement aléatoires et n’ayant aucun lien entre elles (cf. principe de localité). Par conséquent, celles-ci consomment beaucoup plus de ressources que l’exploitation de données ordonnées au sein de la mémoire.
De plus, un portefeuille unique peut contenir plusieurs adresses différentes, sans aucun lien les unes avec les autres. Il est donc impossible de les trier et de les organiser pour accélérer le traitement des transactions.
Lorsque ces paramètres sont assimilés, on constate rapidement que les 15,000 lectures uniques par seconde permises par un SSD, limitent la quantité totale de transactions possibles à 7,500 par seconde, tant qu’on se limite à un fil d’instruction, ou thread, unique.
S’agissant des écritures, elles ne possèdent pas de facteur limitatif dans ce scénario : 55,000 écritures par seconde est envisageable, puisqu’ il n’y a qu’une écriture par transaction « simple ». Nous en restons donc avec cette limite de 7,500 transactions par seconde sur un SSD.
Ce chiffre est cependant obtenu en imaginant un procédé simpliste, avec un seul fil d’instruction. Les SSD modernes permettent cependant jusqu’à 32 fils d’instruction en parallèle, ce qui fait passer le nombre maximal de transactions à 185,000 par seconde environ. Solana et Cloudbreak s’inspirent de cette possibilité.
Comprendre Cloudbreak de Solana
Pour atteindre les performances qui ont fait la réputation de la blockchain Solana, sa conception a été pensée pour que les éléments logiciels fonctionnent en harmonie absolue avec les éléments matériels des serveurs sur lesquels elle se trouve.
Dans le cas présent, le défi le plus complexe est celui de l’organisation de la base de données contenant les soldes de compte, pour qu’il soit possible de la lire et d’y écrire via les 32 fils d’instruction disponibles.
Les bases de données classiques ne font pas usage de cette possibilité, et ne sont pas conçues pour les blockchains de toute façon. Solana utilise donc une base de données spécialisée, qui repose sur plusieurs éléments pour mieux fonctionner.
Le premier de ces éléments est l’utilisation des fichiers mappés en mémoire. Il s’agit de fichiers contenant des informations spécifiques (ici, les soldes de compte), et qui disposent d’un identifiant unique stocké dans la mémoire.

Ce système permet à l’ordinateur d’intégrer, en quelque sorte, ce fichier à la mémoire vive par le biais de la référence, et d’utiliser le contenu du fichier rapidement sans pour autant avoir besoin de tout copier dans la mémoire vive. C’est un compromis entre la vitesse d’accès et l’espace utilisé.
Le deuxième élément dont Solana fait usage via Cloudbreak, provient de l’idée que les opérations séquentielles sont beaucoup plus rapides que les opérations aléatoires. C’est d’ailleurs quelque chose de vrai pour l’intégralité de la mémoire de l’ordinateur.
Les processeurs sont en capacité d’accéder très rapidement à de la mémoire séquentielle. Il s’agit donc de profiter de cette différence, et de mettre un peu d’ordre dans les données issues des blockchains qui ont tendance à être aléatoires. Solana procède de la manière suivante :
- La liste des comptes et des forks est stockée dans la mémoire vive.
- Les comptes sont stockés dans des fichiers mappés en mémoire de 4Mo ou moins.
- Chaque mappage mémoire stocke uniquement des comptes reliés à un unique fork.
- Les mappages sont distribués aléatoirement sur autant de SSD que possible.
- La copie sur écriture (copy-on-write ou COW) est utilisée pour limiter la quantité d’informations dupliquées pour rien.
- Les nouvelles écritures sont ajoutées à un mappage de mémoire aléatoire du fork concerné.
- La liste est mise à jour après que chaque écriture soit terminée.
Puisque les mises à jour des comptes sont réalisées par copie sur écriture et sont inscrites sur un SSD aléatoire, Solana bénéficie à la fois des avantages de l’écriture séquentielle et des avantages d’extensibilité horizontale fournie par l’écriture sur un grand nombre de SSD pour des transactions simultanées.
Les lectures se font toujours en accès aléatoire, mais puisque toute mise à jour d’un fork est nécessairement partagée sur plusieurs SSD, la vitesse de lecture bénéficie aussi d’une meilleure extensibilité horizontale.
Et ce n’est pas tout : Cloudbreak comprend également un mécanisme de récupération des déchets. Lorsque que chaque fork est suffisamment validé par les participants au réseau pour éviter tout retour en arrière et que le solde des comptes est mis à jour, les données correspondant aux vieux comptes désormais invalides sont récupérées et détruites pour libérer de l’espace mémoire.
Enfin, il existe un dernier avantage conféré par l’architecture Cloudbreak : le calcul de la racine Merkle des mises à jour d’un fork est une opération qui peut être réalisée par lecture séquentielle, bénéficiant également de l’amélioration d’extensibilité horizontale des SSD.
Il y a toutefois un inconvénient à cette méthode : les données deviennent moins faciles à comprendre pour un programmeur non familier avec le système. S’agissant d’une structure unique, Cloudbreak n’utilise pas les abstractions classiques que les autres systèmes utilisent pour formuler des requêtes et manipuler les données.
Mise à l’épreuve du système Cloudbreak
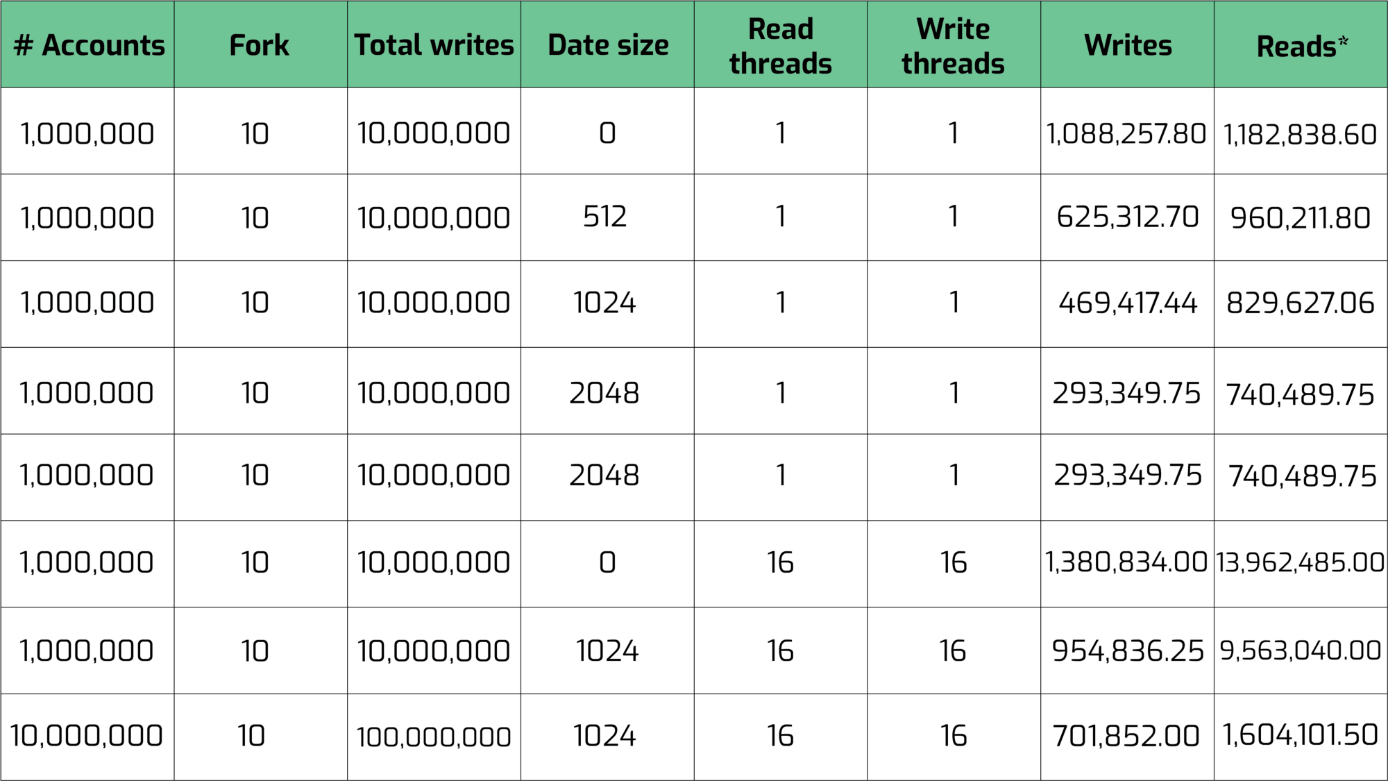
Pendant que le registre des comptes est dans la mémoire vive, nous pouvons constater que le débit correspond à la vitesse d’accès de la mémoire vive, tout en bénéficiant d’une extensibilité dépendant du nombre de cœurs du processeur central.
À partir de 10 millions de comptes, il n’y a plus assez de place dans la mémoire vive pour stocker la base de données entière. Cependant, nous pouvons toujours constater que les performances, avec un seul SSD, ne sont pas loin du million de lectures et d’écritures par seconde.
En pratique, Solana est encore loin de profiter de ce potentiel énorme, mais une chose est sûre : grâce à Cloudbreak, le passage à l’échelle est possible.
Benjamin Martin
Dans la crypto depuis quelques années maintenant, je suis un passionné de nouvelles technologies en général, et plus particulièrement de tous les nouveaux projets crypto qui s’apparentent à la philosophie originelle du Bitcoin. C’est un peu ma quête du Graal, mais avec moins de récipients et de pierres incandescentes.