
Narwhal et Tusk – Mempool et consensus à haute altitude
Narwhal et Tusk sont les deux innovations majeures sur lesquelles s’appuie l’équipe de MystenLabs pour déployer Sui, une plateforme de smart contract décentralisée de dernière génération.
Narwhal est un mempool haut-débit, assurant dissémination et stockage fiables des transactions. Quant à Tusk, il s’agit de son mécanisme de consensus asynchrone et optimisé.
Dans cet article technique, nous allons explorer en profondeur ces deux protocoles avancés, leurs algorithmes, leur implémentations et leurs performances.
Table des matières
Narwhal et la problématique du mempool
En systèmes distribués, nous héritons de décennies de recherches portant sur les protocoles de consensus byzantin et les machines d’état. Élaborer un réseau distribué fiable est une question de compromis entre les différentes propriétés recherchées.
De fait, pour augmenter le débit des systèmes distribués, le paradigme actuel utilise un consensus basé sur un comité de validateurs : on parle de preuve d’enjeu (proof of stake).
Il faut aussi réduire les coûts d’opération de ces algorithmes de consensus. C’est le cas de Hotstuff, le protocole de consensus de Diem (la blockchain de Meta). Un leader y collecte, agrège et diffuse les messages des autres validateurs.
Les chercheurs ayant conçu Narwhal – George Danezis, Lefteris Kokoris-Kogias, Alberto Sonnino et Alexander Spiegelman – ont également travaillé sur Hotstuff, qui sert de base à leur réflexion.
Problématique
Pour améliorer les performances d’un système distribué, la première approche consiste à simplifier les messages encodant les transactions. Mais il y a un autre angle d’attaque : l’architecture générale de leur protocole de diffusion.
Les protocoles partiellement synchrones minimisent le nombre global de messages. Cependant, ils s’appuient sur un leader pour proposer des blocs et coordonner le consensus. Si le leader ne parvient pas à traiter une charge de transactions trop élevée, il devient inévitablement un goulot d’étranglement.
Les messages comportent des métadonnées (par exemple : votes, signatures, hashes). Elles occupent une bande passante minimale, par rapport aux données de transaction (blocs). Puisque les blocs sont d’ordres de grandeur supérieurs (10 Mo) à un message de consensus typique (100 octets), la complexité du message est asymptotique (amortie) pour les comités fixes de taille moyenne (∼ 50 nœuds).
Les protocoles de mempool actuels
On peut qualifier les protocoles de consensus traditionnels de “monolithiques”, car ils regroupent une grande diversité de fonctions – qui pourraient être traitées ailleurs.
Sur Bitcoin par exemple, les logiciels clients diffusent les transactions vers un nœud validateur, qui va ensuite les disséminer en utilisant le protocole de mempool. Une partie de ces transactions est donc partagée plusieurs fois, de façon périodique.
Afin d’améliorer le débit de transactions du réseau, la recherche s’est concentrée sur l’optimisation du protocole de consensus. Une idée est de séparer (lors de la transmission) les métadonnées des messages de taille plus importante, mais elle n’offre pas la garantie de disponibilité du système. En cas de panne réseau, même minime, ces protocoles souffrent terriblement.
Coupler le mempool et la couche de consensus limite le débit global du système. Ces limitations proviennent notamment de la diffusion des transactions pré-consensus.
Optimiser le mempool
Afin de concevoir un registre distribué à hautes performances, les chercheurs se sont focalisés sur l’optimisation du memory pool. L’idée est de le séparer du protocole de consensus.
Ce dernier ne prend en charge que des petites références, de taille fixe. Le débit global du système n’est ainsi, en grande partie, pas affecté par le débit du mécanisme de consensus.
Avec Narwhal, la diffusion des transactions est ainsi limitée au protocole de mempool. Le consensus n’intervient que pour séquencer une très petite quantité de métadonnées, ce qui augmente considérablement les performances du système.
Narwhal, Tusk et performances
Narwhal : un protocole de Mempool avancé garantissant un débit optimal (basé sur la vitesse du réseau) même en mode asynchrone.
Combiné à Hotstuff, le débit augmente, avec un coût modeste en termes de latence.
Les chercheurs ont ensuite tiré parti de la structure de Narwhal pour créer Tusk, un protocole de consensus haut débit, résistant aux attaques DDoS, ne présentant aucun goulot d’étranglement. Tusk dérive de DAG-Rider, et ses performances ont été démontrées même en cas de panne.

Le graphe ci-dessus dépeint les performances d’un système basé sur un mempool classique, puis sur Narwhal, pour différents nombres de validateurs et de machines. On peut remarquer que le débit augmente en tirant parti de la nature parallélisable de Narwhal (en augmentant le nombre de machines).
Conception de Narwhal
Narwhal doit donc assurer la disponibilité et l’intégrité des transactions soumises par un utilisateur sur un réseau pleinement asynchrone.
Cette couche de stockage est distribuée, structurée, persistante, et tolérante aux fautes byzantines. Narwhal fournit disponibilité et ordonnancement partiel des transactions.
Objectifs et hypothèses
Notre système distribué assure la propagation de messages et comporte n participants, dont une minorité f < (n/3) peut être corrompue (faute byzantine).
Par abstraction, dans ce modèle, la communication entre les parties honnêtes est asynchrone et fiable. Les messages peuvent être transmis sous n’importe quel délai, et une portion finie peut finir perdue.
Le mempool de Narwhal permet alors à tous les participants du réseau d’accéder à une abstraction de l’ensemble des blocs de transactions, grâce un système de clé-valeur. Les nœuds maintenant le mempool peuvent accéder aux valeurs stockées dans les blocs de transactions. Il prouvent ensuite à leurs pairs la disponibilité de ces valeurs.
Le mempool de Narwhal est basé sur un graphe orienté acyclique (DAG), construit par rondes successives. Avant d’entrer dans le détail, explorons la structure formelle d’un bloc de transactions composant un nœud de ce DAG.
Structure d’un bloc de transactions
Un bloc (b) de transactions contient les informations suivantes :
- Tout d’abord, la liste des transactions et la liste des références aux blocs précédents ;
- Ensuite, le résumé cryptographique unique de son contenu (digest), d, qui est utilisé comme identifiant pour référencer le bloc ;
- Enfin, les références, encodant une relation de causalité entre les blocs (notée b → b’).
L’ordonnancement des transactions et des références au sein du bloc permet donc d’encoder explicitement leur ordre. De fait, tous les blocs référencés dans un bloc ont été produits avant toutes les transactions dudit bloc.
Opérations
Voici les différentes opérations qu’un nœud validateur peut effectuer :
- Écriture : write(d,b). Stockage d’un block b comportant l’en-tête (le digest) d. En sortie, un certificat de disponibilité, unique, c(d) est émis. Il témoigne du succès de l’opération d’écriture.
- Validation : valid(d,c(d)). Cette opération renvoie “vrai” si le certificat est valide, faux dans le cas contraire.
- Lecture : read(d). Si l’opération write(d,b) est un succès, read(d) renvoie le bloc b.
- Lecture de l’histoire causale : read_causal(d) : retourne l’ensemble de blocs B contenant tous les blocs ayant une relation de causalité avec b.
Ce modèle doit satisfaire un ensemble de propriétés pour remplir ses objectifs.
Propriétés désirées
- Intégrité : pour n’importe quel d, deux opérations read(d) par des parties honnêtes doivent renvoyer la même valeur.
- Disponibilité des blocs : après le succès d’une opération d’écriture write(d,b) pour une partie honnête, une opération de lecture read(d) doit renvoyer b.
- Confinement : soit B l’ensemble renvoyé par read_causal(d). Alors pour tout b’ appartenant à B, l’ensemble B’ renvoyé par read_causal(d’) doit être inclus dans B.
- Causalité des ⅔ : une opération read_causal(d) réussie doit renvoyer un ensemble B contenant au moins deux tiers des blocs écrits avant que l’opération write(d,b) n’ait été invoquée.
- Qualité de la demi-chaîne : au moins la moitié des blocs d’un ensemble B résultant d’une opération read_causal(d) réussie ont été écrits par des parties honnêtes.
Toutes ces propriétés étant remplies, Narwhal doit également être scalable horizontalement. Le débit du protocole doit augmenter avec les ressources allouées par chaque validateur, sans toutefois affecter trop négativement la latence.
Ce sont les propriétés d’intégrité et de disponibilité des blocs qui permettent de séparer la diffusion des données du consensus. Ainsi, la couche consensus sert seulement à ordonnancer les certificats des résumés des blocs, de très petite taille.
Les propriétés de causalité et de confinement assurent que la couche de consensus maintiendra son débit même en cas d’asynchronie. En effet, une fois que le réseau sera à nouveau synchrone, et qu’un résumé de bloc est validé, les validateurs pourront ordonnancer totalement tous les blocs (eux-mêmes ordonnancés causalement) créés durant la période d’asynchronie.
Il est ainsi possible d’utiliser différents protocoles de consensus byzantins avec Narwhal. Leur nature et les conditions réseau vont jouer sur la latence du système.
La dernière propriété (qualité de la demi-chaîne) permet d’assurer la résistance à la censure.
Fonctionnement de Narwhal
Pour les blockchains classiques, la diffusion des transactions est assurée par un protocole de bavardage (gossip protocol). Chaque transaction soumise à un nœud validateur est transmise à tous les autres, de proche en proche. Il y a donc des double-transmissions : la plupart des transactions sont partagées via le mempool, puis les mineurs ou validateurs piochent dedans pour créer un bloc et le partager à leur tour.
Narwhal vise à réduire le besoin de double transmission lorsqu’un bloc est proposé par un leader, et assurer la scalabilité du modèle lorsque des ressources supplémentaires sont disponibles.
Intégrité des transactions
Ce sont des blocs, et non des transactions, qui sont diffusés par les logiciels clients. Le leader propose le hash d’un bloc, en s’appuyant sur le mempool pour prouver son intégrité.
Les validateurs doivent vérifier que les hashes représentent des blocs disponibles. Ils doivent donc les télécharger avant de certifier un bloc.
Disponibilité des blocs
Le certificat d’un bloc prouve que ce dernier est disponible (et peut donc être téléchargé). Chaque bloc du mempool possède un certificat.
Causalité des transactions
Avec la propriété de causalité, on peut émettre un unique certificat pour plusieurs blocs du mempool. En effet, les blocs du mempool incluent les certificats de blocs antérieurs du mempool, issus de l’ensemble des validateurs. Les certificats se réfèrent donc à un bloc et à son histoire causale complète.
Ils sont de taille fixe, ce qui permet de consommer une bande-passante minime. Il y a cependant deux problèmes. Un validateur extrêmement rapide contraint ses pairs à saturer leur bande-passante en générant des blocs trop rapidement. De plus, les validateurs honnêtes pourraient manquer de bande-passante pour partager leurs blocs aux autres.
Qualité de la chaîne
Elle est assurée en imposant des restrictions sur le taux de création des blocs.
Chaque validateur assigne un numéro de ronde à ses blocs. Il doit également joindre un quorum de certificats, issus de la ronde précédente, pour que le bloc soit valide.
Il y a donc toujours des blocs issus de validateurs honnêtes inclus dans chaque proposition. Afin de passer à une nouvelle ronde du mempool, les validateurs doivent attendre que d’autres validateurs honnêtes finissent les rondes précédentes.
Outre une protection contre le flooding, ce mécanisme assure également la résistance à la censure du protocole. En effet, chaque bloc, même émis par un leader malveillant, contiendra toujours au moins 50% de transactions honnêtes. Un adversaire ne peut donc pas « tuer » un leader ont il n’aime pas le bloc proposé.
Scalabilité
Pour assurer cette propriété, les validateurs séparent les blocs en sous-blocs (appelés batches), en fonction du nombre de machines dédiées à la tâche de création des blocs du mempool. Un bloc “primaire” intègre les références aux sous-blocs, dans le mempool.
Cela permet aux validateurs d’allouer des ressources en calcul, stockage et réseau efficacement pour partager ces ensembles de transactions. La scalabilité est quasi linéaire.
Grâce à ces différents piliers, Narwhal permet d’aller plus loin qu’un simple mempool : il s’agit d’une couche de disponibilité et de diffusion des données, robuste et performante.
Architecture de Narwhal
Nous allons entrer dans les détails du protocole central de Narwhal, et comprendre comment il peut ensuite être utilisé pour obtenir un consensus avec un très haut débit de transactions.
Construction d’un bloc
Le mempool de Narwhal est basé sur les concepts de diffusion fiable et de stockage fiable. Il utilise également, pour sa gestion des rondes, les horloges logiques à seuil. Le déroulement des rondes est schématisé ci-dessous.

Déroulé d’une ronde
Chaque validateur maintient sa ronde locale, r. Les validateurs reçoivent des transactions en continu : elles sont disposées dans la liste des certificats (certificate list).
Pour le validateur considéré, lorsque le nombre de certificats provenant de validateurs distincts pour la ronde r – 1 est de 2f + 1, la ronde locale devient r. Il crée et diffuse un bloc pour la nouvelle ronde. Chaque bloc inclut l’identité de son créateur, la ronde locale r, la liste des transactions et des certificats de r – 1, et la signature du créateur.
Règles de validation
Les validateurs diffusent chaque bloc qu’ils créent – pour assurer intégrité et disponibilité du bloc à tous les autres validateurs. Ils vont s’assurer de leur validité et en témoigner via leur signature en vérifiant :
- La signature du créateur ;
- Le numéro de la ronde (elle doit être localement r chez le vérificateur) ;
- Les certificats du bloc pour au moins 2f + 1 blocs de la ronde r – 1 (sauf pour la ronde 0) ;
- Que le validateur a reçu ce bloc en premier – de la part de son créateur, et pour la ronde r.
Si le bloc est valide, il est stocké par les autres validateurs et son résumé (digest) est signé, ainsi que le numéro de ronde et l’identité de son créateur.
En l’absence de correspondance entre le numéro de ronde et la ronde locale du validateur, certains blocs peuvent être refusés. Mais puisque les blocs des rondes futures contiendront 2f + 1 certificats, le validateur “en retard” pourra « avancer » sa ronde locale et signer le nouveau bloc. Dès qu’un créateur obtient le quorum de 2f + 1 pour son bloc, il forge son certificat de disponibilité.
Certification
Le certificat contient l’en-tête du bloc (digest), le numéro de la ronde courante, et l’identité de son créateur.
Le créateur du bloc envoie ce certificat aux autres validateurs, afin qu’ils puissent l’inclure dans leur prochain bloc.
À l’initialisation du système, tous les validateurs créent et certifient des blocs vides pour la ronde r = 0.
Le certificat de disponibilité contient 2f + 1 signatures. Au moins f + 1 validateurs honnêtes ont donc vérifié et stocké le bloc correspondant. Le bloc contient aussi des références : elles permettent de s’assurer que tous les blocs de son histoire causale sont certifiés et disponibles.
Utilisation de Narwhal avec un protocole de consensus
Narwhal doit être couplé à un protocole de consensus adéquat pour obtenir un système distribué à haut débit. Il y a deux options : utiliser un consensus partiellement synchrone, comme Hotstuff ou asynchrone, comme Tusk.
Narwhal et Hotstuff
Les algorithmes de consensus partiellement synchrones peuvent tirer parti de Narwhal pour améliorer leur débit. Prenons l’exemple de Hotstuff ou de LibraBFT. Ils fonctionnent avec un leader, qui propose un bloc de transactions. Ce bloc sera certifié par les autres validateurs.
Avec Narwhal, le leader va proposer un ou plusieurs certificats de disponibilité, en lieu et place du bloc de transactions.
L’histoire causale des certificats (qui n’est pas encore soumise au reste des validateurs) est ordonnancée de façon déterministe, avant sa proposition. Ces relations de causalité s’expriment via le DAG des blocs. L’ordonnancement des blocs sera donc le même pour tous les validateurs, et le consensus est atteint. Il est donc également possible de récupérer tous les blocs soumis et toutes les transactions séquencées (propriété de disponibilité).
Narwhal offre donc d’ores et déjà des avantages pour ce type d’algorithmes de consensus :
- Usage équitable des ressources : sans Narwhal, le leader utilise une grosse quantité de bande-passante, comparativement aux autres validateurs. Avec Narwhal, les données de transaction sont partagées de façon équitable et efficiente en permanence.
- Durant des périodes d’asynchronie (ou lors de pannes byzantines), ces protocoles partiellement synchrones ne permettent pas d’assurer la disponibilité des données. Avec Narwhal, les blocs et leurs certificats de disponibilité continuent d’être forgés. Une fois que le réseau synchronise à nouveau, et que le protocole de consensus soumet un digest, les validateurs fournissent également son histoire causale, qui sera complète, malgré la période d’asynchronie.
Cependant, ces protocoles partiellement synchrones souffrent de problèmes de latence durant les périodes d’asynchronie. C’est ici que Tusk rentre en jeu.

La collecte des déchets
Il s’agit de la limitation principale des algorithmes de consensus basés sur les DAG. On l’appelle la collecte des déchets (garbage collection). Elle provient de l’aspect local de la structure d’un DAG.
Les DAG doivent converger vers la même version chez tous les validateurs. Il est cependant impossible de garantir quand cela va arriver. Tous les validateurs doivent alors garder blocs et certificats immédiatement accessibles, pour aider leurs pairs à rattraper leur retard où traiter d’anciens messages (le fameux garbage).
Sur Narwhal, la structure en 3 rondes permet de pallier ce problème. Les informations concernant la ronde courante suffisent aux validateurs pour certifier un bloc. Ils n’ont pas besoin d’examiner l’historique entier d’un bloc pour effectuer sa vérification.
Afin d’éviter que les validateurs ne tombent en désaccord sur l’histoire causale d’un bloc, dans le cas où ils auraient collecté leur garbage au sein de rondes différentes, Narwhal utilise un protocole de consensus pour s’accorder sur la ronde de collecte des déchets :
- Les blocs des rondes précédentes peuvent donc être stockés hors du validateur principal ;
- Les messages provenant de rondes précédentes peuvent être ignorés.
Narwhal en pratique
Afin d’atteindre les performances théoriques de Narwhal, il faut dans la pratique assurer la diffusion fiable des informations sur le réseau et la scalabilité du système.
Diffusion fiable et quorum
Sur les canaux de communication classiques, une perte de connexion entraîne la perte de l’état de la transmission. Pour assurer une transmission fiable, les protocoles de diffusion utilisent diverses stratégies.
Par exemple, le double écho consiste à établir des canaux de communication « parfait » d’un nœud à un autre (perfect point-to-point channels). Ils vont retransmettre continuellement le même message, jusqu’à s’assurer de sa bonne réception. Cela nécessite une quantité non-plafonnée de mémoire, pour les stocker au niveau de la couche applicative. Ces réseaux restent donc vulnérables aux attaques de déni de service.
Narwhal utilise un système de quorum pour construire le DAG des blocs de transactions ce qui évite de s’appuyer sur des canaux de communication point-par-point.
Mécanisme de diffusion via Narwhal
- Chaque validateur diffuse un bloc pour chaque ronde r
- Lorsque 2f + 1 validateurs le reçoivent, et s’il est valide, ils signent ce bloc. Ces 2f + 1 signatures sont nécessaires pour forger le certificat de disponibilité du bloc. Il sera partagé, et potentiellement inclus dans les blocs de la ronde r + 1.
- Lorsqu’un validateur atteint la ronde r + 1, il cesse la retransmission des messages non-délivrés pour toutes les rondes précédentes.
Le certificat de disponibilité ne permet pas à lui seul d’assurer la fiabilité totale de la transmission. Certains nœuds peuvent ne pas avoir reçu le bloc en question. La fiabilité est assurée de la manière suivante :
- Un bloc de la ronde r + 1 possède un certificat de disponibilité : il contient donc forcément 2f + 1 blocs certifiés pour la ronde r.
- Les validateurs recevant ce bloc de la ronde r + 1 peuvent alors réclamer tous les blocs de son histoire causale aux validateurs ayant signé les certificats.
- Étant donné qu’au moins f + 1 validateurs honnêtes ont stocké chaque bloc, la probabilité d’obtenir la réponse correcte augmente exponentiellement après avoir effectué la requête auprès d’une poignée de validateurs.
C’est un mécanisme résistant aux attaques de déni de service, car il limite le nombre de requêtes nécessaires pour s’assurer de la fiabilité de la transmission. Une savante combinaison entre :
- Les certificats de disponibilité des blocs ;
- Leur inclusion dans des blocs subséquents ;
- Le mécanisme de requête pour obtenir les blocs certifiés manquants.
Validateurs et scalabilité
Narwhal est limité par la bande-passante, la capacité de stockage et de calcul des nœuds du réseau. Afin d’améliorer sa scalabilité, les validateurs peuvent augmenter le nombre de machines dédiées.
Scalabilité horizontale de Narwhal
Voici le diagramme des flux de données entre les différentes machines dédiées des validateurs pour la ronde r.

Les données de transaction sont séparées des métadonnées. Les données de transactions sont acheminées, à travers les différentes machines, avec un taux similaire, grâce à un équilibreur de charge
Chaque machine crée un sous-ensemble de transactions (batch) et le transmet aux autres validateurs. Une fois que le quorum est atteint, le hash du batch est injecté dans le bloc primaire du validateur.
La machine primaire inclut les hashes de ses propres batches, plutôt que les transactions correspondantes. Le bloc primaire ne sera signé que si tous les batches inclus ont bien été stockés par leurs machines dédiées. Toutes les données référencées par le certificat de disponibilité sont ainsi accessibles.
Diffusion
Les blocs primaires sont légers, puisqu’ils contiennent des hashes de batches, et non des transactions. Les différentes machines vont continuellement créer et stocker des batches en tâche de fond. La taille des batches est limitée, pour réduire la latence. De plus, la plupart de ces batches sont donc accessibles aux autres validateurs avant l’arrivée du bloc primaire. Le tout permet :
- De réduire le délai entre la réception d’un bloc primaire et sa signature ;
- Ce faisant, de diffuser en continu de nouveaux batches, pouvant être inclus dans le bloc de la ronde suivante.
Les validateurs vont donc s’adapter à la montée en charge (scalabilité) en ajoutant des machines, ou en augmentant la taille des batches.
La taille des blocs primaires limite donc le débit du système. C’est une limite purement théorique pour l’instant – il faudrait atteindre 12 000 machines par validateur pour que la machine primaire gère des volumes de données similaires à une machine dédiée aux batches.
Tusk, un mécanisme de consensus asynchrone
Tusk est le mécanisme de consensus asynchrone accompagnant Narwhal pour des performances optimales. Inspiré par DAG-Rider, Tusk est une implémentation moderne qui permet d’améliorer considérablement sa latence.
Les validateurs de Tusk utilisent Narwhal comme couche de disponibilité des données – mempool – et incluent dans chacun de leurs blocs un jeton (nombre) généré de façon parfaitement aléatoire. Un tel jeton aléatoire peut être généré via des schémas de signatures à seuil, et les paramètres du schéma définis même en cas d’asynchronie.
L’algorithme de Tusk, grâce au DAG causalement ordonnancé de Narwhal, permet d’ordonnancer totalement les blocs, sans nécessiter de communication supplémentaire. Chaque validateur interprète localement son DAG et utilise le jeton aléatoire pour définir l’ordonnancement final du bloc.
Processus
Le processus est divisé en vagues de 3 rondes consécutives.

- Chaque validateur propose son bloc et son histoire causale.
- Chaque validateur vote pour les propositions, en les incluant dans son bloc.
- Les validateurs élisent, de façon aléatoire, un leader.
Lorsque le jeton aléatoire de la vague est révélé :
- Chaque validateur v soumet le bloc leader élu b d’une vague w s’il y a f + 1 blocs pour le deuxième tour de w (vue locale du DAG de v) faisant référence à b.
- Si c’est le cas, le validateur v ordonnance l’histoire causale de b jusqu’au point de collecte des déchets.
Puisque les vues locales du DAG peuvent diverger selon les validateurs, certains pourraient soumettre un bloc leader dans une vague, et d’autres non.
Afin de garantir que les validateurs honnêtes finiront par ordonnancer les mêmes blocs leaders :
- Une fois qu’un bloc leader est soumis dans une vague w, le validateur v le désigne comme le prochain candidat à être ordonnancé.
- Le validateur v revient à la dernière vague w’, où il a désigné un leader. Pour chaque vague i entre w’ et w, v va vérifier s’il y a un chemin entre le bloc leader candidat et le bloc leader b de la vague i. Si c’est le cas, v ordonnance b avant le candidat actuel, désigne b comme candidat correct, et continue la récursion.
Sécurité
Le mécanisme ci-dessus assure les lemmes suivants :
- Si un validateur soumet un bloc leader b dans une vague i, alors tout bloc leader b’ soumis par un validateur honnête dans une vague future présentera un chemin vers b dans le DAG local du validateur v.
- De même, n’importe quelle paire de validateurs honnêtes soumettra la même séquence de blocs leaders.
Lors de l’ordonnancement d’un bloc leader, chaque validateur ordonnance aussi son histoire causale, selon une règle déterministe. Tous les validateurs honnêtes vont donc faire consensus sur l’ordonnancement total du bloc.
Disponibilité et latence
Le caractère aléatoire de la troisième ronde de chaque vague garantit la disponibilité du système.
En effet, un adversaire ne connaîtra le bloc leader d’une vague qu’après les deux premiers tours. Les f + 1 blocs satisfaisant la règle d’engagement sont définis avant que l’attaquant ne connaisse le bloc leader. La probabilité de soumettre un bloc leader pour chaque vague est donc de (f + 1) / (3f + 1), qui est supérieure à ⅓, même en cas de contrôle total du réseau par l’attaquant.
Ainsi, même en cas d’attaque, l’algorithme de Tusk placera toujours un bloc leader dans le DAG toutes les 7 rondes.
Implémentation de Narwhal et Tusk, performances
Pour leurs travaux initiaux, les chercheurs ont implémenté des validateurs Narwhal multi-cœur en Rust. Le réseau asynchrone est mis en place grâce à Tokio, le schéma de signature (ECDSA) via ed25519-dalek, et les structures de données avec RocksDB. Les canaux de communication point par point utilisent le protocole TCP.
Les expérimentations se sont déroulées sur AWS pour les systèmes suivants :
- Hotstuff de base
- Hotstuff + batching des blocs
- Narwhal et Hotstuff
- Narwhal et Tusk.
Les résultats sont sans appel.
Narwhal en tant que Mempool

- Hotstuff basique : 1800 tx maximum. Latence excellente ~1 seconde.
- Hotstuff + batching : 70 000 tx/s avec 10 autorités, 50 000 tx/s avec un comité de 20 nœuds validateurs. Latence ~2 s.
- Narwhal + Hotstuff : 140 000 tx/s avec une latence < 2 s.
- Narwhal + Tusk : la latence varie en fonction de la taille du comité. Elle est stable ~3 s pour 50 validateurs et un débit de 170 000 tx/s.
La scalabilité de Narwhal
Pour l’évaluer, on mesure le débit en fonction du nombre de machines/instances par validateur.
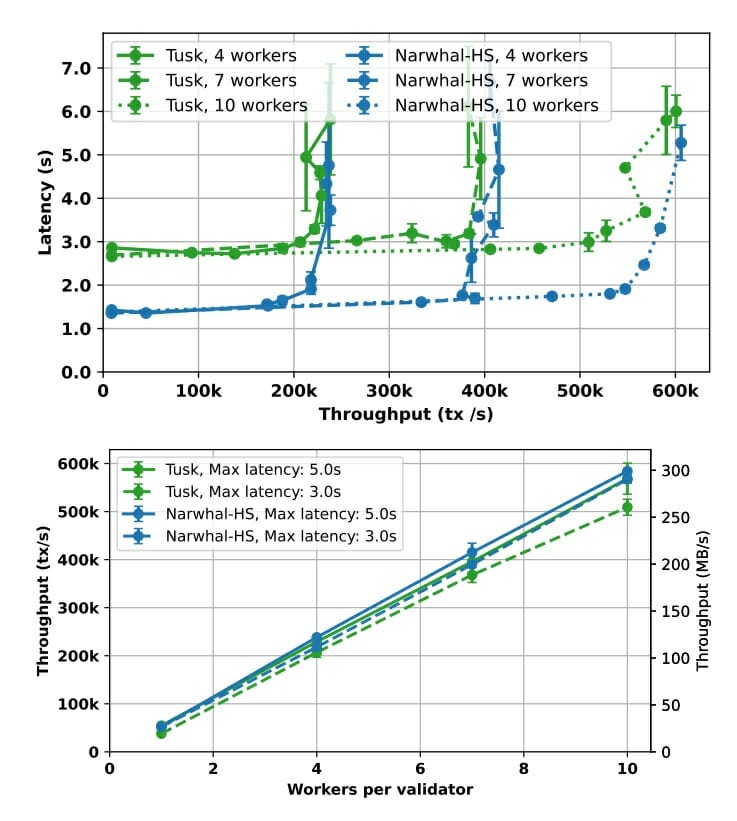
La scalabilité est linéaire, car le débit global est plus ou moins égal au débit de chaque machine multiplié par le nombre de machines.
Fautes byzantines et performances
Le graphique ci-dessous représente la performance des différents systèmes, soumis à un comité validateur de 10 nœuds, en présence de pannes byzantines.

Pour Hotstuff, sans Narwhal, ça ne se passe pas très bien. Le débit chute par un facteur de 5, la latence est 40 fois supérieure.
Avec Narwhal, Tusk et Hotstuff arrivent à maintenir un bon débit. En effet, grâce à la conception du mempool, les transactions continuent d’être collectées et disséminées malgré les fautes. La présence de validateurs malicieux n’entrave pas leur diffusion.
La latence est peu affectée : 4 s avec un validateur défaillant, 6 s avec 3 validateurs défaillants. Narwhal + Hotstuff s’en tire mieux que les variantes de Hotstuff (basique et batching).
Le mot de la fin
Nos deux protocoles, chacun dans leur domaine (mempool et consensus) sont à la pointe de la recherche en système distribués. De nombreux scientifiques ont permis leur élaboration, outre les créateurs de Narwhal et Tusk – George Danezis, Lefteris Kokoris-Kogias, Alberto Sonnino et Alexander Spiegelman.
L’équipe de MystenLabs les a implémenté afin de déployer sa plateforme de smart contracts décentralisée, scalable et à haut débit – Sui.
Pour compléter cette présentation, lire le whitepaper de Narwhal et Tusk.
N’hésitez pas à suivre MystenLabs : Discord – Twitter – LinkedIn – GitHub
Morgan Phuc
Cofondateur du Journal du Coin, passionné de cryptomonnaies depuis 2013 et d'intelligence artificielle. J'aide les francophones à explorer cet écosystème, de la technique à ses aspects les plus méconnus.