
KYVE ouvre son Data Pipeline pour déverser les données sur le Web3
Une info fiable, sécurisée et décentralisée – L’enjeu de la data est absolument central pour l’adoption du Web3. Le projet KYVE Network est en pointe des solutions décentralisées, adoubé par les protocoles les plus populaires et exigeants qui utilisent d’ores et déjà son architecture et ses solutions. Après son réseau Cosmos SDK révélé sur son testnet incitatif Korellia, KYVE dévoile aujourd’hui son Data Pipeline, un outil conçu pour faciliter la vie des développeurs sur l’ensemble de l’écosystème blockchain.
Data Pipeline, du carburant Web3
La version bêta publique sera donc en ligne ce jour, le 5 décembre 2022. A cette date, la communauté pourra enfin officiellement tester concrètement le potentiel du Data Pipeline. Au menu, des capacités inédites et disruptives en matière de partage des données entre les versions 2 et 3 du web qui s’apprêtent à bousculer les habitudes de tous les professionnels qui manipulent quotidiennement ces datas. Pour résumer, Data Pipeline offre un point d’accès facile et personnalisable à toute personne désirant s’en saisir.
Utilisateurs, analystes, ingénieurs en données, développeurs de logiciels, chercheurs, protocoles, tous vont tirer parti de cette nouvelle méthode qui ouvre la voie à de véritables révolutions dans les méthodologies. Ceci afin de pouvoir utiliser les données vérifiées de KYVE, sans pour autant devoir se soucier de récupérer les données originales. Désormais, avec ce produit, les données Web2 peuvent très simplement être sourcées sur les réseaux blockchain et inversement, depuis le Web3 vers Web2, etc…
Une mécanique complexe, une utilisation simplifiée
Ainsi, le Data Pipeline permettra à quiconque d’extraire des données depuis la réserve d’informations collectées et agrégées par KYVE, puis de les importer vers le backend de données de votre choix. En effet, l’équipe a fait en sorte de proposer un outil complet et efficace, compatible avec les protocoles les plus populaires en matière de backend, tels que Snowflake, BigQuery, S3, MongoDB, etc. L’outil est construit sur une structure ELT via la plateforme Airbyte. Une technologie qui autorise la personnalisation des données une fois exportées sur le backend de votre choix.
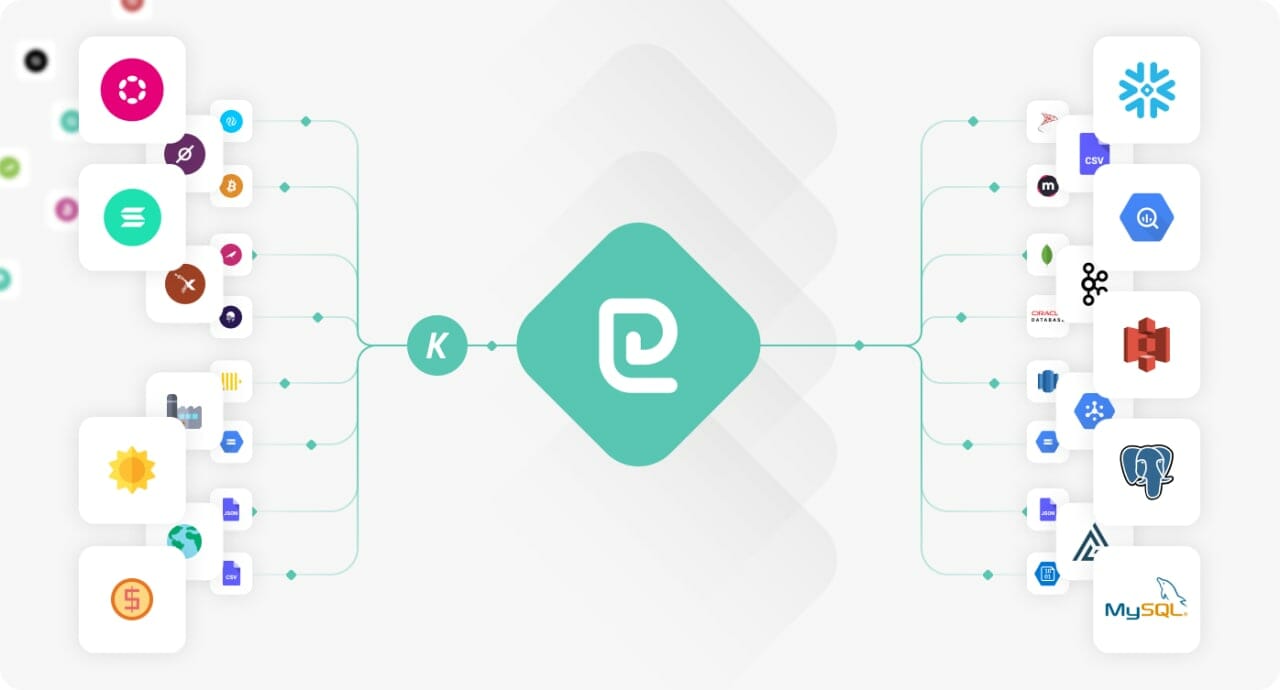
Contrairement à d’autres solutions trop souvent complexes, aucune compétence de codage n’est nécessaire pour l’utiliser. En effet, Data Pipeline a été conçu pour être aussi simple et fluide que possible afin que chacun puisse trouver et utiliser efficacement les données fiables dont il a besoin. Tout le monde peut ainsi utiliser Data Pipeline pour récupérer les données de KYVE et les intégrer dans son projet, ou les utiliser pour son nœud de validation, etc…
Une mise en œuvre personnalisable à l’extrême
Dès aujourd’hui, pour utiliser Data Pipeline, il suffit de visiter le github de KYVE, de télécharger le code et de suivre le guide pas-à-pas afin de le lancer sur votre propre serveur. Une fois installé, vous pouvez immédiatement sélectionner une source personnalisée, tirée de l’un des réserves de données de KYVE, personnaliser les paramètres de synchronisation pour mieux répondre à vos besoins, et abreuver votre propre protocole de toute la data qui vous est nécessaire.
KYVE fonctionne avec des données brutes et publiques, ce qui signifie que lorsque vous les importez à partir de Data Pipeline, vous pouvez les transformer comme bon vous semble pour les adapter à votre cas d’utilisation. Une modularité rendue possible par une structure basée sur le protocole Airbyte qui fournit la technologie de collecte ainsi qu’un connecteur très simple d’utilisation. En outre, toujours grâce à Airbyte, les temps de synchronisation et de mise à jour sont aussi totalement personnalisables.
Depuis la naissance du projet KYVE, sa solution de “pool de data” Web3 permet aux fournisseurs de données de normaliser et valider les flux issus des réseaux blockchain, puis de les conserver sur des sauvegardes en s’appuyant sur des solutions de stockage permanent des données comme Arweave. Ainsi, son architecture garantissait déjà l’immuabilité de ces ressources dans le temps. Aujourd’hui, le tout nouveau Data Pipeline ajoute les qualités d’évolutivité et de disponibilité à ce protocole ô combien nécessaire à la révolution Web3 que nous attendons tous. Pour parachever son œuvre, l’équipe n’attend plus que vous !
Pour ne rien rater des dernières évolutions, rejoignez la communauté de KYVE sur Twitter, Discord et Telegram
Florent C
Père de famille de 49 ans tombé dans le bain crypto en 2017, je suis un passionné de la technologie blockchain, disruptive, libre et décentralisée. J'aime particulièrement apprendre, comprendre et expliquer tous les projets qui permettront à terme d’améliorer nos quotidiens. J’apprécie aussi de commenter à chaud les news de tous les acteurs du cryptogame.